Data about St Andrews Open data
It has been a while, since we stepped back and had a look at what we have collected in our research data repository in St Andrews. So, what has happened since February 2018?
 We have now recorded a total of 1642 dataset records in Pure and linked these up with other information we hold there. 93.9% of our dataset records have at least one publication linked and 63.9% at least one funding project. As part of our daily ‘monitoring’ activities, we are making good use of Pure’s features which let us link up information about the research that takes place in St Andrews. On an individual level, this adds up to a rich set of data about researchers, funding projects, publications and more.
We have now recorded a total of 1642 dataset records in Pure and linked these up with other information we hold there. 93.9% of our dataset records have at least one publication linked and 63.9% at least one funding project. As part of our daily ‘monitoring’ activities, we are making good use of Pure’s features which let us link up information about the research that takes place in St Andrews. On an individual level, this adds up to a rich set of data about researchers, funding projects, publications and more.
Subjects in our data repository
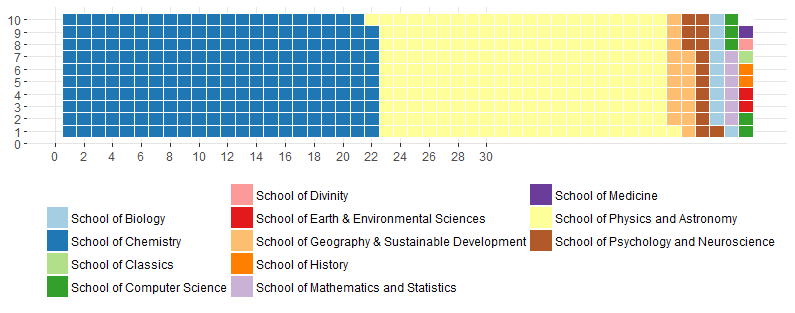
We can also say something about representation of disciplines in our data repository. – A large proportion of the datasets we record are affiliated with the Schools of Chemistry (484 – 31%) and Physics and Astronomy (362 – 24%). This is little surprising, given that these are two of the largest Schools at the University.
However, we are also increasing our collection of data records from schools in the Arts, Humanities and Social Sciences, especially History, Classics, Divinity, Economics and Finance, Art History and English. These include databases and software, catalogues, dictionaries, maps and atlases, scans of museum objects and more. Notably, the majority of these records have been added to our repository since 2018, showing how data preservation and sharing are becoming increasingly relevant in the Arts and Humanities.
Funders driving open data
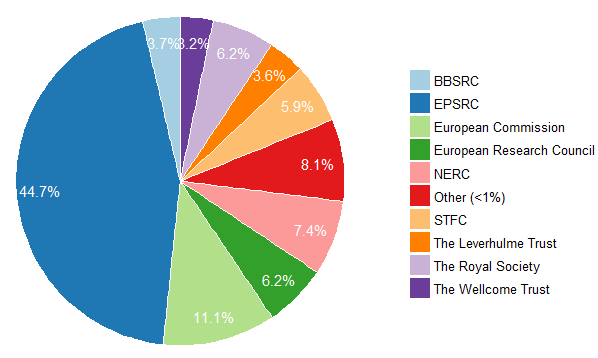
The overall bias towards the physical and biological sciences explains why EPSRC, the European Commission, European Research Council and NERC are the funders most often linked to our dataset records. Each of these funders have clear data sharing policies, which are often main drivers for depositing research data. Keeping track of this link to funding projects gives us an idea how well St Andrews researchers’ data deposit and sharing activities align with funder requirements on data sharing and to tailor our support accordingly.
We do however also record research data produced from projects supported by a range of funders beyond the big UK funders, that don’t have explicit data sharing policies, e.g. the Leverhulme Trust. – Could this be a sign of progress towards data sharing for reasons beyond the need to satisfy funder requirements? We hope so!
Where do St Andrews researchers share their data?
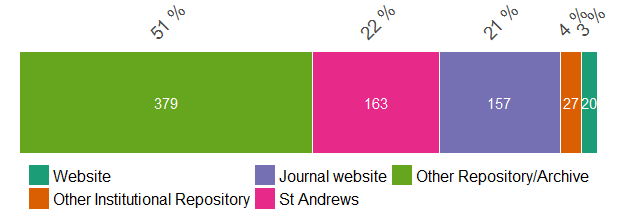
The past 12 months have continued an existing trend among open data records in our repository. The largest proportion of our 746 new dataset records were deposited in professional repositories, such as generic or discipline-specific repositories, Pure or other institutional repositories. These data typically have a DOI and can be maintained, preserved and cited effectively. Still, raw data underpinning publications is also often made available alongside articles on journal websites. While this can be suitable for some data (e.g. supplementary information integral to understanding the article), a professional repository would be a more appropriate home for these in most cases.
Storage, storage, storage
Since 2016, the data volume in our data repository has increased steadily, adding up to a total of 189GB. This is a manageable size and possibly reflects the type of data that has mostly been added so far (numerical data and computational scripts). Looking a bit closer on the dataset level, the largest St Andrews dataset is around 25GB; most datasets are however considerably smaller. Just 35 (7%) are larger than 1GB, while 75% are at most 100MB and 51% are smaller than 15MB.
So, we could say that, if we continued this trend, the widely lamented issue with infrastructure for the storage and sharing of datasets shouldn’t be a problem, right? Or should it?
What is NOT stored
Our conversations with researchers and our RDM Advisory group and a look at the representation among disciplines in our repository suggests that this could be otherwise. Notably, we hold a comparably small number of datasets from Schools, where a significant amount of their research would result in large data volumes (e.g. Biology, Psychology and Neuroscience, Geography and Sustainable Development, Earth and Environmental Sciences).
We know that some of the larger datasets are currently not even stored on our network, but instead on much more insecure, vulnerable and inaccessible external storage devices, for various reasons. At the same time, these data tend to sit at the end of hugely expensive and labour intensive value chains and should be archived and remain accessible. On top, many will be underpinning publications and should as such be publicly available, which is difficult to achieve in these cases.
A proportion of large-scale research data in the fields mentioned above is eligible for storage in national and international data centers. However, we are concerned about data that are can’t be published elsewhere and are continuing to work with researchers in order to archive this data more safely and securely and make it accessible.
Important steps towards archiving data safely and securely and making it accessible are a good data management plan, using centrally managed storage and accounting for data storage and sharing costs in every grant application.
Downloads
The reason why we publish research data is of course to make it available to other researchers and the wider public. How do we know it’s been worthwhile? Citation of datasets by those who used the data is one way to look at this, which is why we advocate for everyone to properly cite data or code they re-use in their work. Citations and Altmetrics are well used metrics for assessing the interest generated by a publication and over time, the same should be the case for data and software.
For data, we can do a bit more though. Here, we can also have a look at the number of times a dataset has been downloaded from our website. After all, there isn’t much one can do with a dataset or code file without downloading it. This is where some interesting patterns emerge:
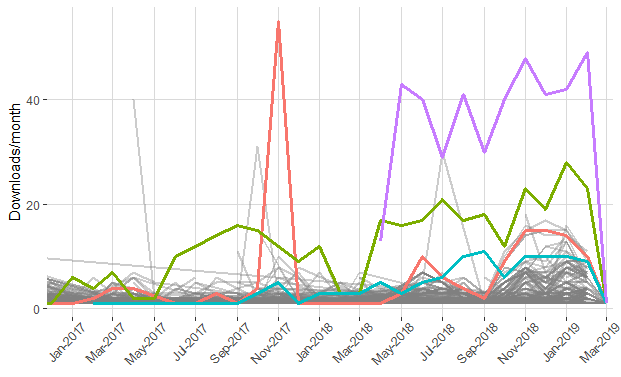
Some datasets have for been downloaded particularly often during their lifetime (> 400 times). Others might have been downloaded fewer times overall, but were downloaded more often at specific times, with sudden spikes or slower waves in the number of downloads per month, like in the download stats for four datasets highlihgted in the graph.
What drove these downloads? Was it a paper, poster, conference presentation or just a chat to the right person at the right time? – This is material for interesting data stories which we hope to share more often in our research data management blog. Are you interested in telling us your data story? – Just get in touch!
The raw data used for the above analysis contains confidential and/or business relevant information and can therefore not be made publicly available. Please don’t hesitate to contact us for further information.