Our Research Data Management journey, #lovedata18
In our third post to mark Love Data Week 2018 we will talk about what the RDM team have been up to during the past years.
The RDM team was formed in May 2015 as a response to the EPSRC policy on research data and with the aim of advising and supporting researchers at the University of St Andrews in navigating this new landscape of policies and data management. Initially consisting of one member of staff, the team has since grown to two members (!). Below we look in more details at our main activities.
Advocacy and training
One of our first tasks was raising awareness of new data policies and…of our existence, of course! In order to achieve this, we organised talks to Schools in the form of brief presentations at School councils, one-hour long training sessions, informal coffee break meetings, drop-in sessions, in essence, any format that the Schools deemed suitable. Our main focus so far has been the science-based Schools and we have been to eight of the nine Schools in the Faculty of Science and the Faculty of Medicine. We still have to reach some of the Schools especially from the Faculty of Arts and the Faculty of Divinity, so if you would like us to visit your School, email us at [email protected].
In January 2016, we were invited by one of the Schools to deliver a training session. As part of this, we were asked to produce a simple and visual guide informing researchers on when they should create dataset records, ask for DOIs and deposit their data files. In collaboration with the Open Access team, we developed a deposit workflow mapped against the article lifecycle (Fina, Proven 2017). This new workflow encourages the creation of a dataset record just before the article is submitted for publication, giving us enough time to reserve a DOI and several opportunities for the researchers to add it to the manuscript. Only after the article is accepted researchers can upload the files and we can register (mint) the DOI with DataCite. We have included the workflow in our data deposit guidance document and we present it in every training we deliver with the aim to make it common practice.
Another approach to further raising awareness of research data policies is what we call our “monitoring process”. On a daily basis, we check articles added to our institutional repository for any reference to underpinning data. If a reference to underpinning data is present, we mark the record as having a data access statement. We then follow the statement and if we can locate the data, we create a dataset record in Pure. On the other hand, if no data access statement is present in the article we contact the authors directly, informing them of the relevant funders’ policies (if they exist). This might be considered a time consuming process, but it helps us discovering datasets that our researchers have deposited elsewhere and that we wouldn’t be otherwise aware of.
Finally, we also organised training for University of St Andrews staff and postgraduate students. For academic and research staff we offer two training events, both running several times a year: an introductory training session covering different topics, including data policies and the benefits of data sharing (‘Managing Your Research Information: impact, open access, Pure, data management’); and a more in depth session looking at how to publish, license data, and how to use Pure for data deposit (‘Managing Research Information: publishing research data’).
For postgraduate students we offer a workshop that runs twice a year and covers research data management best practices, and how to publish data. In addition to this training session, we deliver a short presentation on the benefits of research data management at the postgraduate induction that takes place several times during the academic year.
If you are interested in any of the above training sessions, book your place via the CAPOD website.
Datasets stats
It is safe to say that all the advocacy and training is starting to have an impact. As Figure 1 shows, since January 2016, the number of dataset records in Pure has grown to more than 1000 and over one third of these are datasets deposited in St Andrews (36%). That is: 5005 files with an average of 25 megabytes per file and a total size of 125 gigabytes. We also create reference records for datasets deposited elsewhere such as other data repositories (34%), journal websites (22%), other institutional repositories (4%) or websites (4%). Why the jump in the number of datasets (especially reference records) towards the end of 2017? Well, that is when the RDM team grew to two members, which gave a boost to our monitoring process!
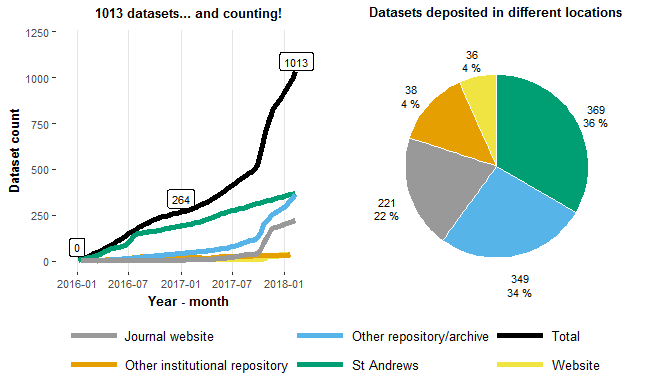
On average so far, we have created 95% of the reference datasets records currently in Pure. These records are mostly created as a result of our article monitoring process. With regards to data deposited in St Andrews (where data files are uploaded in Pure), we have contributed to the creation of 49% of these records. This is typically in response to researchers requesting DOIs for inclusion in publications as part of data access statements. Requests are usually made at any stage of the article publication lifecycle, however our advice of creating datasets records before submitting the manuscript to the journal is being taken on board more and more often, as Figure 2 shows. Shortly after the introduction of the new deposit workflow (January 2016) we start seeing a delay in the growth of the number of minted DOIs compared to the number of dataset records created. This is because records tend to be created before the submission of the manuscript while the DOI is minted only after article acceptance (a few weeks later).
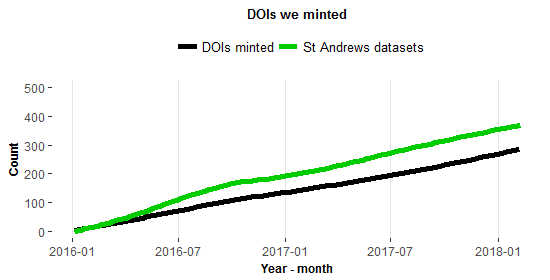
In summary, we are seeing a steady increase in the number of dataset records created and in the requests for DOIs (currently 320 DOIs registered with DataCite). Ideally, of course, we would like more of the datasets to be created by researchers, so we are constantly working to improve our workflows and advice to make the deposit process smoother.
Data management Plans
As part of our service we also offer support with the writing of data management plans for all funders. We review already-written plans or we help writing them from a blank template. So far, we have helped with 18 data management plans for submission to a variety of funders: H2020, BBSRC, ESRC, MRC, AHRC, Wellcome Trust and Royal Society. These consultations take from as little as a few minutes to up to hours. The longest consultations tend to be for Horizon 2020 data management plans and H2020 require more than one data management plan to be submitted during the life of the research project. Therefore, for these plans we can be involved for several days spread over a period of a few years.
How do researchers come to us for data management plan consultations? Most researchers are pointed in our direction by their colleagues or by the University Research Business Development and Contracts (RBDC) team.
Even though we have been involved in the writing of a few data management plans, we believe that this component of the service could be used more across the University, so if you are reading this and need help with your data management plan for your grant application, just email us at [email protected] and we will be more than happy to assist!
RDM Advisory Group
The RDM Advisory Group was formed in May 2017 and it brings together a representative from each School, from the Library (RDM Team) and from IT services. The group meets a few times a year with the aim of discussing RDM needs, issues and opportunities. The representatives gather opinions and suggestions from their Schools and submit them to the group’s meetings for discussion. The RDM Advisory Group currently have 13 School representatives (out of 19 Schools) and met twice since May 2017. If you are interested in joining the group, email us at [email protected].
What’s next?
What are we planning to do over the next six months? Continue with our business as usual, of course! But in addition to this, we would like to extend our advocacy to the Arts and Humanities Schools and review the current training offering. One of the outcomes of the last RDM Advisory Group meeting was to offer tailored training for the Sciences and for the Arts and Humanities. We would also like to start looking at download statistics for datasets with the aim of providing download information to our researchers.
We are also moving our website from its current location and while doing so we are restructuring it. The new website will be housed under the Library webpages and hopefully we will make it live by the end of March 2018.
And finally, we would like to write blog posts more frequently in order to avoid lengthy posts like this one!
The RDM Team:
Federica Fina https://orcid.org/0000-0003-2594-350X
Eva Borger https://orcid.org/0000-0003-4965-2969